DECLARE_PER_CPU(structtask_struct*,current_task);static__always_inlinestructtask_struct*get_current(void){returnthis_cpu_read_stable(current_task);}#define current get_current()
/* Real parent process: */structtask_struct__rcu*real_parent;/* Recipient of SIGCHLD, wait4() reports: */structtask_struct__rcu*parent;/* Children/sibling form the list of natural children: */structlist_headchildren;structlist_headsibling;
/* CLONE_PARENT re-uses the old parent */if(clone_flags&(CLONE_PARENT|CLONE_THREAD)){p->real_parent=current->real_parent;p->parent_exec_id=current->parent_exec_id;}else{p->real_parent=current;p->parent_exec_id=current->self_exec_id;}
/*
* Called when a process ceases being the active-running process involuntarily
* due, typically, to expiring its time slice (this may also be called when
* switching to the idle task). Now we can calculate how long we ran.
* Also, if the process is still in the TASK_RUNNING state, call
* sched_info_queued() to mark that it has now again started waiting on
* the runqueue.
*/staticinlinevoidsched_info_depart(structrq*rq,structtask_struct*t){unsignedlonglongdelta=rq_clock(rq)-t->sched_info.last_arrival;rq_sched_info_depart(rq,delta);if(t->state==TASK_RUNNING)sched_info_queued(rq,t);}
/*
* Per process flags
*/#define PF_IDLE 0x00000002 /* I am an IDLE thread */#define PF_EXITING 0x00000004 /* Getting shut down */#define PF_EXITPIDONE 0x00000008 /* PI exit done on shut down */#define PF_VCPU 0x00000010 /* I'm a virtual CPU */#define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */#define PF_FORKNOEXEC 0x00000040 /* Forked but didn't exec */#define PF_MCE_PROCESS 0x00000080 /* Process policy on mce errors */#define PF_SUPERPRIV 0x00000100 /* Used super-user privileges */#define PF_DUMPCORE 0x00000200 /* Dumped core */#define PF_SIGNALED 0x00000400 /* Killed by a signal */#define PF_MEMALLOC 0x00000800 /* Allocating memory */#define PF_NPROC_EXCEEDED 0x00001000 /* set_user() noticed that RLIMIT_NPROC was exceeded */#define PF_USED_MATH 0x00002000 /* If unset the fpu must be initialized before use */#define PF_USED_ASYNC 0x00004000 /* Used async_schedule*(), used by module init */#define PF_NOFREEZE 0x00008000 /* This thread should not be frozen */#define PF_FROZEN 0x00010000 /* Frozen for system suspend */#define PF_KSWAPD 0x00020000 /* I am kswapd */#define PF_MEMALLOC_NOFS 0x00040000 /* All allocation requests will inherit GFP_NOFS */#define PF_MEMALLOC_NOIO 0x00080000 /* All allocation requests will inherit GFP_NOIO */#define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */#define PF_KTHREAD 0x00200000 /* I am a kernel thread */#define PF_RANDOMIZE 0x00400000 /* Randomize virtual address space */#define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */#define PF_MEMSTALL 0x01000000 /* Stalled due to lack of memory */#define PF_UMH 0x02000000 /* I'm an Usermodehelper process */#define PF_NO_SETAFFINITY 0x04000000 /* Userland is not allowed to meddle with cpus_allowed */#define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */#define PF_MEMALLOC_NOCMA 0x10000000 /* All allocation request will have _GFP_MOVABLE cleared */#define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */#define PF_SUSPEND_TASK 0x80000000 /* This thread called freeze_processes() and should not be frozen */
/*
* Only the _current_ task can read/write to tsk->flags, but other
* tasks can access tsk->flags in readonly mode for example
* with tsk_used_math (like during threaded core dumping).
* There is however an exception to this rule during ptrace
* or during fork: the ptracer task is allowed to write to the
* child->flags of its traced child (same goes for fork, the parent
* can write to the child->flags), because we're guaranteed the
* child is not running and in turn not changing child->flags
* at the same time the parent does it.
*/
权限
和权限相关的成员如下:
1
2
3
4
5
6
7
/* Process credentials: *//* Tracer's credentials at attach: */conststructcred__rcu*ptracer_cred;/* Objective and real subjective task credentials (COW): */conststructcred__rcu*real_cred;/* Effective (overridable) subjective task credentials (COW): */conststructcred__rcu*cred;
structcred{atomic_tusage;#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_tsubscribers;/* number of processes subscribed */void*put_addr;unsignedmagic;#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_tuid;/* real UID of the task */kgid_tgid;/* real GID of the task */kuid_tsuid;/* saved UID of the task */kgid_tsgid;/* saved GID of the task */kuid_teuid;/* effective UID of the task */kgid_tegid;/* effective GID of the task */kuid_tfsuid;/* UID for VFS ops */kgid_tfsgid;/* GID for VFS ops */// .......
kernel_cap_tcap_inheritable;/* caps our children can inherit */kernel_cap_tcap_permitted;/* caps we're permitted */kernel_cap_tcap_effective;/* caps we can actually use */kernel_cap_tcap_bset;/* capability bounding set */kernel_cap_tcap_ambient;/* Ambient capability set */// .......
}__randomize_layout;
/*
* The security context of a task
*
* The parts of the context break down into two categories:
*
* (1) The objective context of a task. These parts are used when some other
* task is attempting to affect this one.
*
* (2) The subjective context. These details are used when the task is acting
* upon another object, be that a file, a task, a key or whatever.
*
* Note that some members of this structure belong to both categories - the
* LSM security pointer for instance.
*
* A task has two security pointers. task->real_cred points to the objective
* context that defines that task's actual details. The objective part of this
* context is used whenever that task is acted upon.
*
* task->cred points to the subjective context that defines the details of how
* that task is going to act upon another object. This may be overridden
* temporarily to point to another security context, but normally points to the
* same context as task->real_cred.
*/
运行统计
主要是task的一些时间相关的状态信息.
1
2
3
4
5
6
7
8
9
u64utime;//用户态消耗的CPU时间
u64stime;//内核态消耗的CPU时间
/* Context switch counts: */unsignedlongnvcsw;//自愿的上下文切换计数
unsignedlongnivcsw;//非自愿的上下文切换计数
/* Monotonic time in nsecs: */u64start_time;//进程启动时间, 不包含睡眠时间
/* Boot based time in nsecs: */u64real_start_time;//进程启动时间, 包含睡眠时间
/* Signal handlers: */structsignal_struct*signal;structsighand_struct*sighand;sigset_tblocked;sigset_treal_blocked;/* Restored if set_restore_sigmask() was used: */sigset_tsaved_sigmask;structsigpendingpending;unsignedlongsas_ss_sp;size_tsas_ss_size;unsignedintsas_ss_flags;
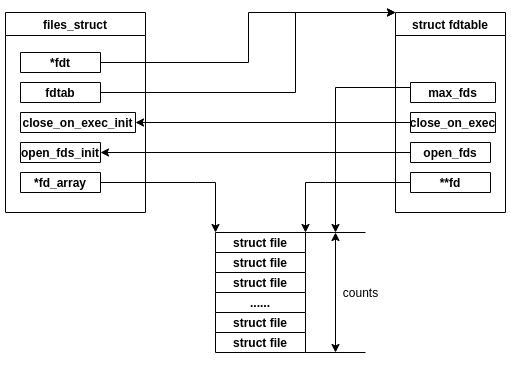
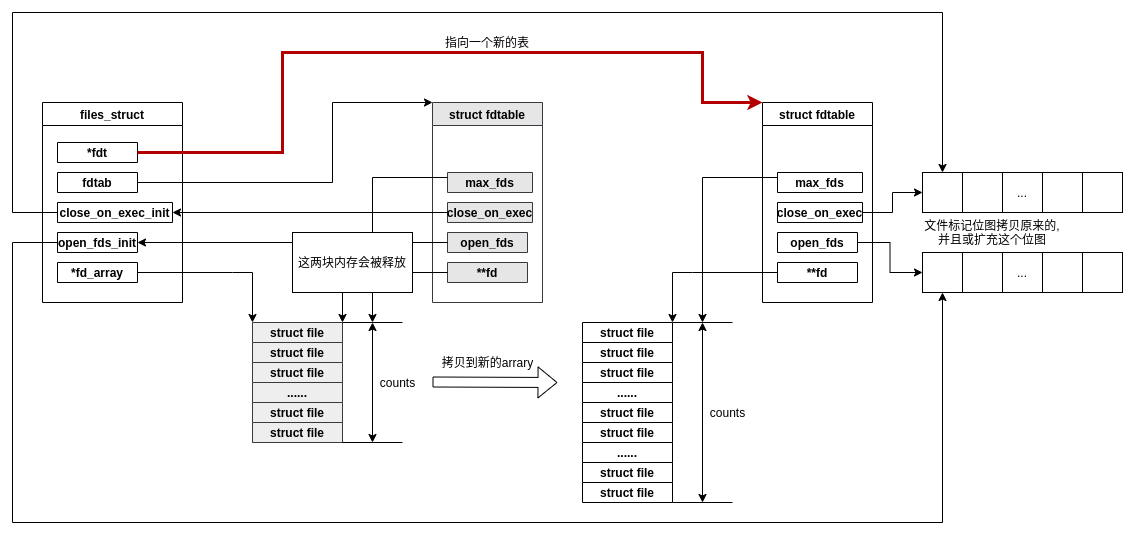
/*
* Open file table structure
*/structfiles_struct{/* read mostly part */atomic_tcount;boolresize_in_progress;wait_queue_head_tresize_wait;structfdtable__rcu*fdt;structfdtablefdtab;/* written part on a separate cache line in SMP */spinlock_tfile_lock____cacheline_aligned_in_smp;unsignedintnext_fd;unsignedlongclose_on_exec_init[1];unsignedlongopen_fds_init[1];unsignedlongfull_fds_bits_init[1];structfile__rcu*fd_array[NR_OPEN_DEFAULT];};