drwxrwxr-x 3 mi mi 4096 4月 27 19:32 .
drwxrwxr-x 7 mi mi 4096 4月 26 10:02 ..
-rw-rw-r-- 1 mi mi 0 4月 26 10:03 file_attr
drwxrwxr-x 2 mi mi 4096 4月 27 19:32 file_dic
$ ls -la filesystem/
total 12
drwxrwxrwx 3 mi mi 4096 5月 11 20:36 .
drwxrwxrwx 11 mi mi 4096 5月 8 20:32 ..
-rw-rw-r-- 1 mi mi 0 5月 8 20:32 file_attr
drwxrwxr-x 2 mi mi 4096 5月 11 20:36 file_dic
/*
* Keep mostly read-only and often accessed (especially for
* the RCU path lookup and 'stat' data) fields at the beginning
* of the 'struct inode'
*/structinode{umode_ti_mode;// 文件权限, rwx等
unsignedshorti_opflags;kuid_ti_uid;// 文件所属用户id, ls可以看到
kgid_ti_gid;// 文件所属用户组id, ls可以看到
unsignedinti_flags;#ifdef CONFIG_FS_POSIX_ACL
structposix_acl*i_acl;structposix_acl*i_default_acl;#endif
conststructinode_operations*i_op;structsuper_block*i_sb;// 指向了super block, 对同一个文件系统是唯一的
structaddress_space*i_mapping;//......
/* Stat data, not accessed from path walking */unsignedlongi_ino;/*
* Filesystems may only read i_nlink directly. They shall use the
* following functions for modification:
*
* (set|clear|inc|drop)_nlink
* inode_(inc|dec)_link_count
*/union{constunsignedinti_nlink;unsignedint__i_nlink;};dev_ti_rdev;loff_ti_size;// 文件大小
structtimespec64i_atime;// 操作时间相关
structtimespec64i_mtime;// 操作时间相关
structtimespec64i_ctime;// 操作时间相关
spinlock_ti_lock;/* i_blocks, i_bytes, maybe i_size */unsignedshorti_bytes;u8i_blkbits;u8i_write_hint;blkcnt_ti_blocks;//......
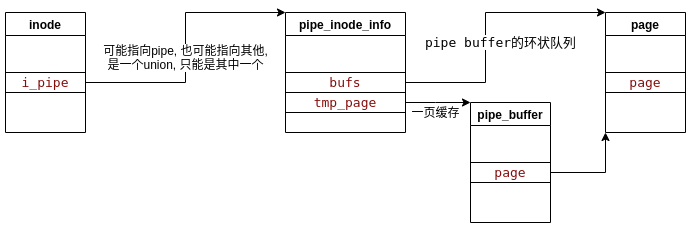
union{structpipe_inode_info*i_pipe;structblock_device*i_bdev;structcdev*i_cdev;char*i_link;unsignedi_dir_seq;};// inode的类型, 比如可以是一个pipe或者link等, 这时候可以不需要磁盘上具体的文件内容, 仅inode结构就可以了
//......
}__randomize_layout;
/*
* Structure of an inode on the disk
*/structext4_inode{__le16i_mode;/* File mode */__le16i_uid;/* Low 16 bits of Owner Uid */__le32i_size_lo;/* Size in bytes */__le32i_atime;/* Access time */__le32i_ctime;/* Inode Change time */__le32i_mtime;/* Modification time */__le32i_dtime;/* Deletion Time */__le16i_gid;/* Low 16 bits of Group Id */__le16i_links_count;/* Links count */__le32i_blocks_lo;/* Blocks count */__le32i_flags;/* File flags *///.......
__le32i_block[EXT4_N_BLOCKS];/* Pointers to blocks */__le32i_generation;/* File version (for NFS) */__le32i_file_acl_lo;/* File ACL */__le32i_size_high;__le32i_obso_faddr;/* Obsoleted fragment address *///......
};
/**
* struct pipe_inode_info - a linux kernel pipe
* @mutex: mutex protecting the whole thing
* @wait: reader/writer wait point in case of empty/full pipe
* @nrbufs: the number of non-empty pipe buffers in this pipe
* @buffers: total number of buffers (should be a power of 2)
* @curbuf: the current pipe buffer entry
* @tmp_page: cached released page
* @readers: number of current readers of this pipe
* @writers: number of current writers of this pipe
* @files: number of struct file referring this pipe (protected by ->i_lock)
* @waiting_writers: number of writers blocked waiting for room
* @r_counter: reader counter
* @w_counter: writer counter
* @fasync_readers: reader side fasync
* @fasync_writers: writer side fasync
* @bufs: the circular array of pipe buffers
* @user: the user who created this pipe
**/structpipe_inode_info{structmutexmutex;wait_queue_head_twait;unsignedintnrbufs,curbuf,buffers;unsignedintreaders;unsignedintwriters;unsignedintfiles;unsignedintwaiting_writers;unsignedintr_counter;unsignedintw_counter;structpage*tmp_page;structfasync_struct*fasync_readers;structfasync_struct*fasync_writers;structpipe_buffer*bufs;structuser_struct*user;};
pipe_buffer的结构内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/**
* struct pipe_buffer - a linux kernel pipe buffer
* @page: the page containing the data for the pipe buffer
* @offset: offset of data inside the @page
* @len: length of data inside the @page
* @ops: operations associated with this buffer. See @pipe_buf_operations.
* @flags: pipe buffer flags. See above.
* @private: private data owned by the ops.
**/structpipe_buffer{structpage*page;unsignedintoffset,len;conststructpipe_buf_operations*ops;unsignedintflags;unsignedlongprivate;};
structsuper_block{structlist_heads_list;/* Keep this first */dev_ts_dev;/* search index; _not_ kdev_t */unsignedchars_blocksize_bits;unsignedlongs_blocksize;loff_ts_maxbytes;/* Max file size */structfile_system_type*s_type;conststructsuper_operations*s_op;conststructdquot_operations*dq_op;conststructquotactl_ops*s_qcop;conststructexport_operations*s_export_op;unsignedlongs_flags;unsignedlongs_iflags;/* internal SB_I_* flags */unsignedlongs_magic;structdentry*s_root;// 根结点dentry
structrw_semaphores_umount;ints_count;atomic_ts_active;//......
structhlist_bl_heads_roots;/* alternate root dentries for NFS */structlist_heads_mounts;/* list of mounts; _not_ for fs use */structblock_device*s_bdev;structbacking_dev_info*s_bdi;structmtd_info*s_mtd;structhlist_nodes_instances;unsignedints_quota_types;/* Bitmask of supported quota types */structquota_infos_dquot;/* Diskquota specific options */structsb_writerss_writers;//......
chars_id[32];/* Informational name */uuid_ts_uuid;/* UUID */unsignedints_max_links;fmode_ts_mode;/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/structmutexs_vfs_rename_mutex;/* Kludge *//*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/constchar*s_subtype;conststructdentry_operations*s_d_op;/* default d_op for dentries *//*
* Saved pool identifier for cleancache (-1 means none)
*/intcleancache_poolid;structshrinkers_shrink;/* per-sb shrinker handle *//* Number of inodes with nlink == 0 but still referenced */atomic_long_ts_remove_count;/* Pending fsnotify inode refs */atomic_long_ts_fsnotify_inode_refs;/* Being remounted read-only */ints_readonly_remount;/* AIO completions deferred from interrupt context */structworkqueue_struct*s_dio_done_wq;structhlist_heads_pins;/*
* Owning user namespace and default context in which to
* interpret filesystem uids, gids, quotas, device nodes,
* xattrs and security labels.
*/structuser_namespace*s_user_ns;/*
* The list_lru structure is essentially just a pointer to a table
* of per-node lru lists, each of which has its own spinlock.
* There is no need to put them into separate cachelines.
*/structlist_lrus_dentry_lru;structlist_lrus_inode_lru;structrcu_headrcu;structwork_structdestroy_work;structmutexs_sync_lock;/* sync serialisation lock *//*
* Indicates how deep in a filesystem stack this SB is
*/ints_stack_depth;/* s_inode_list_lock protects s_inodes */spinlock_ts_inode_list_lock____cacheline_aligned_in_smp;structlist_heads_inodes;/* all inodes */spinlock_ts_inode_wblist_lock;structlist_heads_inodes_wb;/* writeback inodes */}__randomize_layout;
structdentry{/* RCU lookup touched fields */unsignedintd_flags;/* protected by d_lock */seqcount_td_seq;/* per dentry seqlock */structhlist_bl_noded_hash;/* lookup hash list */structdentry*d_parent;/* parent directory */structqstrd_name;structinode*d_inode;/* Where the name belongs to - NULL is
* negative */unsignedchard_iname[DNAME_INLINE_LEN];/* small names *//* Ref lookup also touches following */structlockrefd_lockref;/* per-dentry lock and refcount */conststructdentry_operations*d_op;structsuper_block*d_sb;/* The root of the dentry tree */unsignedlongd_time;/* used by d_revalidate */void*d_fsdata;/* fs-specific data */union{structlist_headd_lru;/* LRU list */wait_queue_head_t*d_wait;/* in-lookup ones only */};structlist_headd_child;/* child of parent list */structlist_headd_subdirs;/* our children *//*
* d_alias and d_rcu can share memory
*/union{structhlist_noded_alias;/* inode alias list */structhlist_bl_noded_in_lookup_hash;/* only for in-lookup ones */structrcu_headd_rcu;}d_u;}__randomize_layout;