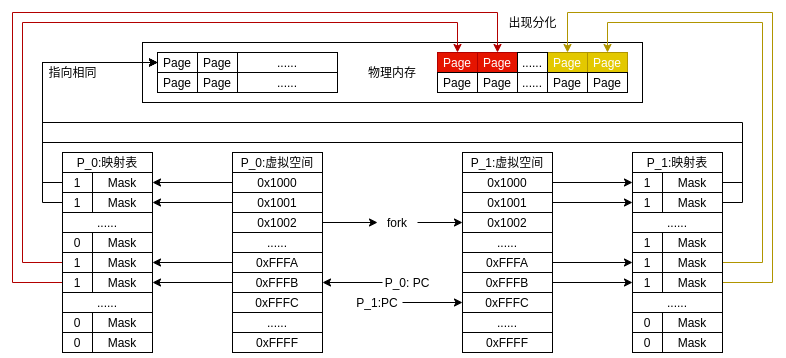
structtask_struct{#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/structthread_infothread_info;#endif
/* -1 unrunnable, 0 runnable, >0 stopped: */volatilelongstate;/*
* This begins the randomizable portion of task_struct. Only
* scheduling-critical items should be added above here.
*/randomized_struct_fields_startvoid*stack;refcount_tusage;/* Per task flags (PF_*), defined further below: */unsignedintflags;unsignedintptrace;#ifdef CONFIG_SMP
structllist_nodewake_entry;inton_cpu;#ifdef CONFIG_THREAD_INFO_IN_TASK
/* Current CPU: */unsignedintcpu;#endif
unsignedintwakee_flips;unsignedlongwakee_flip_decay_ts;structtask_struct*last_wakee;/*
* recent_used_cpu is initially set as the last CPU used by a task
* that wakes affine another task. Waker/wakee relationships can
* push tasks around a CPU where each wakeup moves to the next one.
* Tracking a recently used CPU allows a quick search for a recently
* used CPU that may be idle.
*/intrecent_used_cpu;intwake_cpu;#endif
inton_rq;intprio;intstatic_prio;intnormal_prio;unsignedintrt_priority;conststructsched_class*sched_class;structsched_entityse;structsched_rt_entityrt;#ifdef CONFIG_CGROUP_SCHED
structtask_group*sched_task_group;#endif
structsched_dl_entitydl;#ifdef CONFIG_PREEMPT_NOTIFIERS
/* List of struct preempt_notifier: */structhlist_headpreempt_notifiers;#endif
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsignedintbtrace_seq;#endif
unsignedintpolicy;intnr_cpus_allowed;cpumask_tcpus_allowed;#ifdef CONFIG_PREEMPT_RCU
intrcu_read_lock_nesting;unionrcu_specialrcu_read_unlock_special;structlist_headrcu_node_entry;structrcu_node*rcu_blocked_node;#endif /* #ifdef CONFIG_PREEMPT_RCU */#ifdef CONFIG_TASKS_RCU
unsignedlongrcu_tasks_nvcsw;u8rcu_tasks_holdout;u8rcu_tasks_idx;intrcu_tasks_idle_cpu;structlist_headrcu_tasks_holdout_list;#endif /* #ifdef CONFIG_TASKS_RCU */structsched_infosched_info;structlist_headtasks;#ifdef CONFIG_SMP
structplist_nodepushable_tasks;structrb_nodepushable_dl_tasks;#endif
structmm_struct*mm;structmm_struct*active_mm;/* Per-thread vma caching: */structvmacachevmacache;#ifdef SPLIT_RSS_COUNTING
structtask_rss_statrss_stat;#endif
intexit_state;intexit_code;intexit_signal;/* The signal sent when the parent dies: */intpdeath_signal;/* JOBCTL_*, siglock protected: */unsignedlongjobctl;/* Used for emulating ABI behavior of previous Linux versions: */unsignedintpersonality;/* Scheduler bits, serialized by scheduler locks: */unsignedsched_reset_on_fork:1;unsignedsched_contributes_to_load:1;unsignedsched_migrated:1;unsignedsched_remote_wakeup:1;#ifdef CONFIG_PSI
unsignedsched_psi_wake_requeue:1;#endif
/* Force alignment to the next boundary: */unsigned:0;/* Unserialized, strictly 'current' *//* Bit to tell LSMs we're in execve(): */unsignedin_execve:1;unsignedin_iowait:1;#ifndef TIF_RESTORE_SIGMASK
unsignedrestore_sigmask:1;#endif
#ifdef CONFIG_MEMCG
unsignedin_user_fault:1;#endif
#ifdef CONFIG_COMPAT_BRK
unsignedbrk_randomized:1;#endif
#ifdef CONFIG_CGROUPS
/* disallow userland-initiated cgroup migration */unsignedno_cgroup_migration:1;#endif
#ifdef CONFIG_BLK_CGROUP
/* to be used once the psi infrastructure lands upstream. */unsigneduse_memdelay:1;#endif
unsignedlongatomic_flags;/* Flags requiring atomic access. */structrestart_blockrestart_block;pid_tpid;pid_ttgid;#ifdef CONFIG_STACKPROTECTOR
/* Canary value for the -fstack-protector GCC feature: */unsignedlongstack_canary;#endif
/*
* Pointers to the (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*//* Real parent process: */structtask_struct__rcu*real_parent;/* Recipient of SIGCHLD, wait4() reports: */structtask_struct__rcu*parent;/*
* Children/sibling form the list of natural children:
*/structlist_headchildren;structlist_headsibling;structtask_struct*group_leader;/*
* 'ptraced' is the list of tasks this task is using ptrace() on.
*
* This includes both natural children and PTRACE_ATTACH targets.
* 'ptrace_entry' is this task's link on the p->parent->ptraced list.
*/structlist_headptraced;structlist_headptrace_entry;/* PID/PID hash table linkage. */structpid*thread_pid;structhlist_nodepid_links[PIDTYPE_MAX];structlist_headthread_group;structlist_headthread_node;structcompletion*vfork_done;/* CLONE_CHILD_SETTID: */int__user*set_child_tid;/* CLONE_CHILD_CLEARTID: */int__user*clear_child_tid;u64utime;u64stime;#ifdef CONFIG_ARCH_HAS_SCALED_CPUTIME
u64utimescaled;u64stimescaled;#endif
u64gtime;structprev_cputimeprev_cputime;#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
structvtimevtime;#endif
#ifdef CONFIG_NO_HZ_FULL
atomic_ttick_dep_mask;#endif
/* Context switch counts: */unsignedlongnvcsw;unsignedlongnivcsw;/* Monotonic time in nsecs: */u64start_time;/* Boot based time in nsecs: */u64real_start_time;/* MM fault and swap info: this can arguably be seen as either mm-specific or thread-specific: */unsignedlongmin_flt;unsignedlongmaj_flt;#ifdef CONFIG_POSIX_TIMERS
structtask_cputimecputime_expires;structlist_headcpu_timers[3];#endif
/* Process credentials: *//* Tracer's credentials at attach: */conststructcred__rcu*ptracer_cred;/* Objective and real subjective task credentials (COW): */conststructcred__rcu*real_cred;/* Effective (overridable) subjective task credentials (COW): */conststructcred__rcu*cred;/*
* executable name, excluding path.
*
* - normally initialized setup_new_exec()
* - access it with [gs]et_task_comm()
* - lock it with task_lock()
*/charcomm[TASK_COMM_LEN];structnameidata*nameidata;#ifdef CONFIG_SYSVIPC
structsysv_semsysvsem;structsysv_shmsysvshm;#endif
#ifdef CONFIG_DETECT_HUNG_TASK
unsignedlonglast_switch_count;unsignedlonglast_switch_time;#endif
/* Filesystem information: */structfs_struct*fs;/* Open file information: */structfiles_struct*files;/* Namespaces: */structnsproxy*nsproxy;/* Signal handlers: */structsignal_struct*signal;structsighand_struct*sighand;sigset_tblocked;sigset_treal_blocked;/* Restored if set_restore_sigmask() was used: */sigset_tsaved_sigmask;structsigpendingpending;unsignedlongsas_ss_sp;size_tsas_ss_size;unsignedintsas_ss_flags;structcallback_head*task_works;#ifdef CONFIG_AUDIT
#ifdef CONFIG_AUDITSYSCALL
structaudit_context*audit_context;#endif
kuid_tloginuid;unsignedintsessionid;#endif
structseccompseccomp;/* Thread group tracking: */u32parent_exec_id;u32self_exec_id;/* Protection against (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, mempolicy: */spinlock_talloc_lock;/* Protection of the PI data structures: */raw_spinlock_tpi_lock;structwake_q_nodewake_q;#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task: */structrb_root_cachedpi_waiters;/* Updated under owner's pi_lock and rq lock */structtask_struct*pi_top_task;/* Deadlock detection and priority inheritance handling: */structrt_mutex_waiter*pi_blocked_on;#endif
#ifdef CONFIG_DEBUG_MUTEXES
/* Mutex deadlock detection: */structmutex_waiter*blocked_on;#endif
#ifdef CONFIG_TRACE_IRQFLAGS
unsignedintirq_events;unsignedlonghardirq_enable_ip;unsignedlonghardirq_disable_ip;unsignedinthardirq_enable_event;unsignedinthardirq_disable_event;inthardirqs_enabled;inthardirq_context;unsignedlongsoftirq_disable_ip;unsignedlongsoftirq_enable_ip;unsignedintsoftirq_disable_event;unsignedintsoftirq_enable_event;intsoftirqs_enabled;intsoftirq_context;#endif
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 48UL
u64curr_chain_key;intlockdep_depth;unsignedintlockdep_recursion;structheld_lockheld_locks[MAX_LOCK_DEPTH];#endif
#ifdef CONFIG_UBSAN
unsignedintin_ubsan;#endif
/* Journalling filesystem info: */void*journal_info;/* Stacked block device info: */structbio_list*bio_list;#ifdef CONFIG_BLOCK
/* Stack plugging: */structblk_plug*plug;#endif
/* VM state: */structreclaim_state*reclaim_state;structbacking_dev_info*backing_dev_info;structio_context*io_context;#ifdef CONFIG_COMPACTION
structcapture_control*capture_control;#endif
/* Ptrace state: */unsignedlongptrace_message;kernel_siginfo_t*last_siginfo;structtask_io_accountingioac;#ifdef CONFIG_PSI
/* Pressure stall state */unsignedintpsi_flags;#endif
#ifdef CONFIG_TASK_XACCT
/* Accumulated RSS usage: */u64acct_rss_mem1;/* Accumulated virtual memory usage: */u64acct_vm_mem1;/* stime + utime since last update: */u64acct_timexpd;#endif
#ifdef CONFIG_CPUSETS
/* Protected by ->alloc_lock: */nodemask_tmems_allowed;/* Seqence number to catch updates: */seqcount_tmems_allowed_seq;intcpuset_mem_spread_rotor;intcpuset_slab_spread_rotor;#endif
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock: */structcss_set__rcu*cgroups;/* cg_list protected by css_set_lock and tsk->alloc_lock: */structlist_headcg_list;#endif
#ifdef CONFIG_X86_CPU_RESCTRL
u32closid;u32rmid;#endif
#ifdef CONFIG_FUTEX
structrobust_list_head__user*robust_list;#ifdef CONFIG_COMPAT
structcompat_robust_list_head__user*compat_robust_list;#endif
structlist_headpi_state_list;structfutex_pi_state*pi_state_cache;#endif
#ifdef CONFIG_PERF_EVENTS
structperf_event_context*perf_event_ctxp[perf_nr_task_contexts];structmutexperf_event_mutex;structlist_headperf_event_list;#endif
#ifdef CONFIG_DEBUG_PREEMPT
unsignedlongpreempt_disable_ip;#endif
#ifdef CONFIG_NUMA
/* Protected by alloc_lock: */structmempolicy*mempolicy;shortil_prev;shortpref_node_fork;#endif
#ifdef CONFIG_NUMA_BALANCING
intnuma_scan_seq;unsignedintnuma_scan_period;unsignedintnuma_scan_period_max;intnuma_preferred_nid;unsignedlongnuma_migrate_retry;/* Migration stamp: */u64node_stamp;u64last_task_numa_placement;u64last_sum_exec_runtime;structcallback_headnuma_work;structnuma_group*numa_group;/*
* numa_faults is an array split into four regions:
* faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer
* in this precise order.
*
* faults_memory: Exponential decaying average of faults on a per-node
* basis. Scheduling placement decisions are made based on these
* counts. The values remain static for the duration of a PTE scan.
* faults_cpu: Track the nodes the process was running on when a NUMA
* hinting fault was incurred.
* faults_memory_buffer and faults_cpu_buffer: Record faults per node
* during the current scan window. When the scan completes, the counts
* in faults_memory and faults_cpu decay and these values are copied.
*/unsignedlong*numa_faults;unsignedlongtotal_numa_faults;/*
* numa_faults_locality tracks if faults recorded during the last
* scan window were remote/local or failed to migrate. The task scan
* period is adapted based on the locality of the faults with different
* weights depending on whether they were shared or private faults
*/unsignedlongnuma_faults_locality[3];unsignedlongnuma_pages_migrated;#endif /* CONFIG_NUMA_BALANCING */#ifdef CONFIG_RSEQ
structrseq__user*rseq;u32rseq_len;u32rseq_sig;/*
* RmW on rseq_event_mask must be performed atomically
* with respect to preemption.
*/unsignedlongrseq_event_mask;#endif
structtlbflush_unmap_batchtlb_ubc;structrcu_headrcu;/* Cache last used pipe for splice(): */structpipe_inode_info*splice_pipe;structpage_fragtask_frag;#ifdef CONFIG_TASK_DELAY_ACCT
structtask_delay_info*delays;#endif
#ifdef CONFIG_FAULT_INJECTION
intmake_it_fail;unsignedintfail_nth;#endif
/*
* When (nr_dirtied >= nr_dirtied_pause), it's time to call
* balance_dirty_pages() for a dirty throttling pause:
*/intnr_dirtied;intnr_dirtied_pause;/* Start of a write-and-pause period: */unsignedlongdirty_paused_when;#ifdef CONFIG_LATENCYTOP
intlatency_record_count;structlatency_recordlatency_record[LT_SAVECOUNT];#endif
/*
* Time slack values; these are used to round up poll() and
* select() etc timeout values. These are in nanoseconds.
*/u64timer_slack_ns;u64default_timer_slack_ns;#ifdef CONFIG_KASAN
unsignedintkasan_depth;#endif
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack: */intcurr_ret_stack;intcurr_ret_depth;/* Stack of return addresses for return function tracing: */structftrace_ret_stack*ret_stack;/* Timestamp for last schedule: */unsignedlonglongftrace_timestamp;/*
* Number of functions that haven't been traced
* because of depth overrun:
*/atomic_ttrace_overrun;/* Pause tracing: */atomic_ttracing_graph_pause;#endif
#ifdef CONFIG_TRACING
/* State flags for use by tracers: */unsignedlongtrace;/* Bitmask and counter of trace recursion: */unsignedlongtrace_recursion;#endif /* CONFIG_TRACING */#ifdef CONFIG_KCOV
/* Coverage collection mode enabled for this task (0 if disabled): */unsignedintkcov_mode;/* Size of the kcov_area: */unsignedintkcov_size;/* Buffer for coverage collection: */void*kcov_area;/* KCOV descriptor wired with this task or NULL: */structkcov*kcov;#endif
#ifdef CONFIG_MEMCG
structmem_cgroup*memcg_in_oom;gfp_tmemcg_oom_gfp_mask;intmemcg_oom_order;/* Number of pages to reclaim on returning to userland: */unsignedintmemcg_nr_pages_over_high;/* Used by memcontrol for targeted memcg charge: */structmem_cgroup*active_memcg;#endif
#ifdef CONFIG_BLK_CGROUP
structrequest_queue*throttle_queue;#endif
#ifdef CONFIG_UPROBES
structuprobe_task*utask;#endif
#if defined(CONFIG_BCACHE) || defined(CONFIG_BCACHE_MODULE)
unsignedintsequential_io;unsignedintsequential_io_avg;#endif
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
unsignedlongtask_state_change;#endif
intpagefault_disabled;#ifdef CONFIG_MMU
structtask_struct*oom_reaper_list;#endif
#ifdef CONFIG_VMAP_STACK
structvm_struct*stack_vm_area;#endif
#ifdef CONFIG_THREAD_INFO_IN_TASK
/* A live task holds one reference: */refcount_tstack_refcount;#endif
#ifdef CONFIG_LIVEPATCH
intpatch_state;#endif
#ifdef CONFIG_SECURITY
/* Used by LSM modules for access restriction: */void*security;#endif
#ifdef CONFIG_GCC_PLUGIN_STACKLEAK
unsignedlonglowest_stack;unsignedlongprev_lowest_stack;#endif
/*
* New fields for task_struct should be added above here, so that
* they are included in the randomized portion of task_struct.
*/randomized_struct_fields_end/* CPU-specific state of this task: */structthread_structthread;/*
* WARNING: on x86, 'thread_struct' contains a variable-sized
* structure. It *MUST* be at the end of 'task_struct'.
*
* Do not put anything below here!
*/};
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
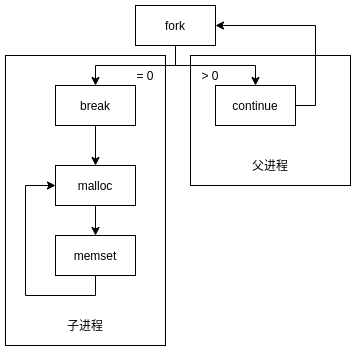
*/long_do_fork(unsignedlongclone_flags,unsignedlongstack_start,unsignedlongstack_size,int__user*parent_tidptr,int__user*child_tidptr,unsignedlongtls){structcompletionvfork;structpid*pid;structtask_struct*p;inttrace=0;longnr;// 根据clone_flags判断clone分支
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/if(!(clone_flags&CLONE_UNTRACED)){if(clone_flags&CLONE_VFORK)trace=PTRACE_EVENT_VFORK;elseif((clone_flags&CSIGNAL)!=SIGCHLD)trace=PTRACE_EVENT_CLONE;elsetrace=PTRACE_EVENT_FORK;if(likely(!ptrace_event_enabled(current,trace)))trace=0;}//根据clone_flags copy_process
p=copy_process(clone_flags,stack_start,stack_size,child_tidptr,NULL,trace,tls,NUMA_NO_NODE);add_latent_entropy();if(IS_ERR(p))returnPTR_ERR(p);/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/trace_sched_process_fork(current,p);pid=get_task_pid(p,PIDTYPE_PID);nr=pid_vnr(pid);if(clone_flags&CLONE_PARENT_SETTID)put_user(nr,parent_tidptr);if(clone_flags&CLONE_VFORK){p->vfork_done=&vfork;init_completion(&vfork);get_task_struct(p);}//唤醒子进程
wake_up_new_task(p);/* forking complete and child started to run, tell ptracer */if(unlikely(trace))ptrace_event_pid(trace,pid);if(clone_flags&CLONE_VFORK){if(!wait_for_vfork_done(p,&vfork))ptrace_event_pid(PTRACE_EVENT_VFORK_DONE,pid);}put_pid(pid);returnnr;}
#ifdef __USE_GNU
/* Cloning flags. */# define CSIGNAL 0x000000ff /* Signal mask to be sent at exit. */# define CLONE_VM 0x00000100 /* Set if VM shared between processes. */# define CLONE_FS 0x00000200 /* Set if fs info shared between processes. */# define CLONE_FILES 0x00000400 /* Set if open files shared between processes. */# define CLONE_SIGHAND 0x00000800 /* Set if signal handlers shared. */# define CLONE_PTRACE 0x00002000 /* Set if tracing continues on the child. */# define CLONE_VFORK 0x00004000 /* Set if the parent wants the child to
wake it up on mm_release. */# define CLONE_PARENT 0x00008000 /* Set if we want to have the same
parent as the cloner. */# define CLONE_THREAD 0x00010000 /* Set to add to same thread group. */# define CLONE_NEWNS 0x00020000 /* Set to create new namespace. */# define CLONE_SYSVSEM 0x00040000 /* Set to shared SVID SEM_UNDO semantics. */# define CLONE_SETTLS 0x00080000 /* Set TLS info. */# define CLONE_PARENT_SETTID 0x00100000 /* Store TID in userlevel buffer
before MM copy. */# define CLONE_CHILD_CLEARTID 0x00200000 /* Register exit futex and memory
location to clear. */# define CLONE_DETACHED 0x00400000 /* Create clone detached. */# define CLONE_UNTRACED 0x00800000 /* Set if the tracing process can't
force CLONE_PTRACE on this clone. */# define CLONE_CHILD_SETTID 0x01000000 /* Store TID in userlevel buffer in
the child. */# define CLONE_NEWCGROUP 0x02000000 /* New cgroup namespace. */# define CLONE_NEWUTS 0x04000000 /* New utsname group. */# define CLONE_NEWIPC 0x08000000 /* New ipcs. */# define CLONE_NEWUSER 0x10000000 /* New user namespace. */# define CLONE_NEWPID 0x20000000 /* New pid namespace. */# define CLONE_NEWNET 0x40000000 /* New network namespace. */# define CLONE_IO 0x80000000 /* Clone I/O context. */#endif
上述调用的fork函数定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork){#ifdef CONFIG_MMU
//17 = 0x11
return_do_fork(SIGCHLD,0,0,NULL,NULL,0);#else
/* can not support in nommu mode */return-EINVAL;#endif
}#endif
# define CLONE_VM 0x00000100 /* Set if VM shared between processes. */
# define CLONE_VFORK 0x00004000 /* Set if the parent wants the child to
wake it up on mm_release. */
intaddone(int*n){*n=21;printf("[%d %d] add one %d\n",getppid(),getpid(),(*n));}intmain(){volatileintn=0;void*st;st=malloc(FIBER_STACK);if(!st){printf("error malloc\n");return-1;}printf("create clone\n");printf("[%d %d] before add %d\n",getppid(),getpid(),n);clone(&addone,(char*)st+FIBER_STACK,CLONE_VM|CLONE_VFORK,&n);printf("[%d %d] after add %d\n",getppid(),getpid(),n);free(st);return1;}
输出是:
1
2
3
4
create clone
[29629 25737] before add 0
[25737 25738] add one 21
[29629 25737] after add 21