进程、线程和协程概念
概念
问题: 什么是进程/线程/协程? 为什么要有这些概念?
读了一些文章, 要讲清楚这几个概念篇幅会很大, 所以会作为一个小专题来分享. 这篇的目的就是宏观上要对进程/线程/协程有基本的概念.
进程
一般来说, 进程是操作系统资源分配和调度的最小单位. 运行一个程序, 我们会说这个程序占了多少内存, CPU利用率是多少, 磁盘读写效率是多少等等, 内存/CPU/磁盘等等都是进程的资源. 换句话说, 在资源分配的问题上, 可以认为操作系统只认进程, 一切资源都是按照进程为单位分配的.
进程是动态的, 只有在程序运行的时候才会有进程资源的分配; 程序则是静态的, 程序是躺在磁盘中的数据; 进程就是程序运行的一个实例; 一个程序可以有很多个进程, 比如我们打开Chrome的时候, 可以在后台看到多个Chrome进程对应Chrome这一个程序.
对用户来说, 一般是不需要过度关心进程资源的, 这些都是操作系统帮我们做了. 比如写完一段代码, 运行它, 代码是在磁盘上的, 怎么加载进内存, 需要分配多少内存空间, 需要如何调度这个程序, 都是由操作系统完成, 用户无需干预.
在多任务时代, CPU一般是不会将其精力一直放在某一个进程上的, 而是雨露均沾, 会给每一个进程都分配一定的时间片用来执行(和操作系统的调度算法有关). 这里就会涉及到进程的切换, 进程切换是需要保存和加载进程上下文的, 进程的上下文就是与该进程执行相关的一些参数和配置.
进程的上下文
简单记录进程上下文的大概内容:
- 各种寄存器
- 内存映射信息
- 环境变量信息, 比如程序所在目录等信息
- 打开的设备或者文件信息, 比如权限等信息
- 进程运行状态信息, 比如各种进程数据和堆栈信息
- 系统信息, 对进程管理和控制的信息, 比如进程任务结构体和内核堆栈(不太明白)
进程的内存资源
虚拟内存
问题: 程序从磁盘加载到内存的时候, 程序中的函数/变量等等都是用地址指代的, 也就是说, 编译完成之后, 这些地址是固定的. 如果同时运行两个程序, 他们的地址空间恰好冲突了怎么办?
这个问题在单核单任务时代是不那么容易出现的, 因为系统一次只跑一个进程, 跑完一个进程才会跑下一个进程, 所以基本不存在内存冲突的问题. 但是在多任务时代, 则是非常严重的问题, 编译器无法为每个程序分配不同的内存地址以保证不冲突.
这时候就用到了虚拟内存空间.
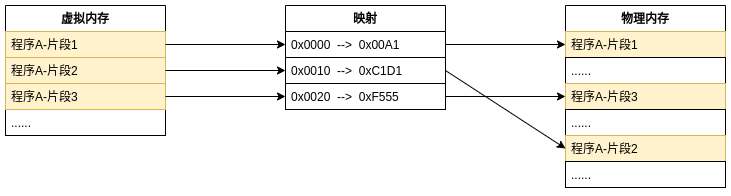
虚拟内存空间通俗的说就是假的内存空间, 它欺骗了进程, 让进程以为它有了整个物理内存的资源, 甚至更大. 比如一段代码编译之后, 某个变量a的地址在P, 编译时仅仅是给了一个虚拟的内存地址, 当然对于进程来说, 这个地址和真正的物理地址没有区别, 通过虚拟内存技术进程是完全无需关心的. 在程序执行的时候, 系统会为程序随机地分配一定的物理内存空间, 然后将程序加载进内存. 这时候的变量a对进程来说地址还是P, 但是对物理内存来说, 地址可能变成了Q, 程序退出下次再执行的时候, 变量a的物理地址又可能变成R. 那么, 当要访问变量a的时候怎么办呢? 这时候我只知道a的虚拟地址无法拿到它的物理地址啊.
操作系统的做法是建立内存映射表, 将进程的虚拟内存空间映射到物理内存空间. 有了映射关系, 就可以很容易的通过虚拟内存找到物理内存, 从而访问对应的值了.
如果是每一个虚拟地址都有映射关系, 也引发其他的问题: 我们至少需要两个空间(比如说都是8B)存储一个映射关系, 即[虚拟地址, 物理地址]. 如果对每个虚拟地址都有这样的映射关系的话, 可能会浪费至少两倍的内存. 怎么办呢?
解决方法是不要对每个地址都建立映射关系, 而是对一段连续的地址建立映射关系, 这就是页. 比如规定每个页的大小是1KB, 则1KB的空间只需要一个映射关系就可以表示, 即[页首地址, 物理地址]. 当从磁盘将程序装载进内存的时候, 根据映射表每次都在物理内存上开辟一页的空间. 当需要访问某个变量时, 通过变量虚拟地址在这一页的偏移和页首地址的映射关系就可以得到这个变量在物理内存中的物理地址.
然而, 程序一般都不是一次性加载进内存的.
内存映射表
问题: 内存映射表是如何建立且如何访问的呢?
上述中, 我们讲到了比较朴素的内存映射的结构是[虚拟地址, 物理地址].
实际上内存映射表一般结构是这样的: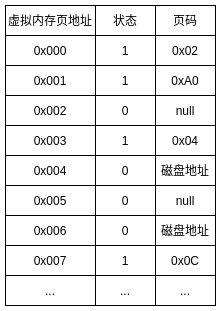
物理内存和虚拟内存一样, 都按照一页一页的划分. 在内存映射表中, 实际上是将虚拟内存的页映射到物理内存页上.
状态一栏表示虚拟内存页的状态, 一般分为三种:
- 已缓存, 在物理内存上已经缓存了对应的数据
- 未缓存, 物理内存上还没有缓存对应数据, 数据还在磁盘上
- 未分配, 没有用到的虚拟内存空间
CPU寻址内存映射表的时候, 如果遇到是已缓存状态(物理内存地址), 则转到对应物理内存上操作; 如果遇到未缓存状态(磁盘地址), 则触发缺页中断, 在物理内存上找到空闲页, 并将磁盘对应页上的数据复制到物理内存对应页上, 然后继续执行; 如果遇到的是未分配状态(空), 则不操作即可.
这就可以解释C++中new等内存分配操作需要在运行时才可能检查出异常行为的原因了. 因为new等内存分配操作只是在虚拟内存中分配了内存, 只有在运行状态, 且运行到对应指令时才会在物理内存上分配空间, 所以分配失败/越界等问题要在运行时才可能触发.
线程
线程则是比进程更细的操作单位. 一个进程至少要有一个或者可以有多个线程, 并且这些线程都共享这个进程的资源. 这也说明, 当编写多线程程序的时候, 我们可以直接用一些变量来传递不同线程之间的数据, 因为同一个进程的不同线程的内存资源是共享的, 这些线程使用了同一个虚拟内存空间和内存映射表.
一般会把进程看作是静态的, 它只负责资源的管理, 把线程看作是动态的, 线程负责资源的执行, 线程是程序的实际执行者.
线程和进程的关系是这样的:
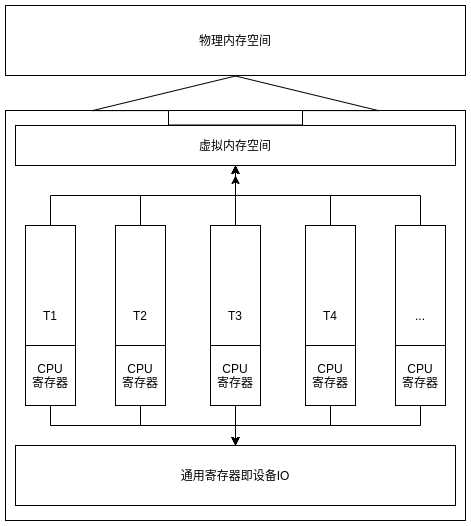
最大的方框代表进程, 包含了多个线程/虚拟内存空间/寄存器和IO设备等, T1-T4代表是进程中的线程.
进程可能有多个线程, 线程共享进程的虚拟内存空间和通用寄存器即IO设备等, 每个线程也有自己CPU寄存器, 所以在线程切换的时候, 相比进程切换, 不需要保存内存映射/设备/通用寄存器等信息, 一般只需保存线程的调用栈和CPU寄存器等信息. 所以线程切换的开销会比进程切换的开销更低.
通过这个图我们也可以理解, 线程就是流水线, 帮助工厂(进程)完成一定的功能. 所以线程一般是合作的, 共同完整进程的一部分功能.
协程
以上, 我们已经知道:
- 进程是系统资源管理的最小单元;
- 线程是系统任务执行的最小单元;
- 进程和线程都是由操作系统管理;
线程的调度是操作系统控制的, 所以会涉及到内核态的上下文切换; 协程是完全由用户控制的, 和操作系统无关, 不会涉及到内核态的上下文切换.
TODO: 有几个点难以理解, 暂时记录这么多. (1. 需要一个较好的例子, 理解协程和串行的区别; 2. 要理解一些协程库的作用, 不切换到内核态是怎么实现协程切换的?)